2025年国内大模型网关产品深度评测:技术架构、性能与实践
引言
随着大语言模型从实验室走向生产环境,企业对AI基础设施的要求越来越高。大模型网关(LLM Gateway)作为连接业务系统与多个LLM服务商的关键中间层,已成为企业AI架构的标准配置。
市面上的大模型网关产品琳琅满目:有完全开源的社区项目,有功能丰富的商业产品,也有云厂商的托管服务。如何在众多方案中选择最适合自己业务场景的产品?
本文将从技术架构、核心能力、性能表现、部署运维、成本考量五个维度,对国内主流大模型网关产品进行全面、深入、客观的对比分析,并结合实际测试数据和企业实践案例,为技术决策提供参考。
一、评测维度与方法论
1.1 评测对象
本次评测选取了国内最具代表性的四类大模型网关方案:
- 深度赋能大模型网关(LLM Gateway)- 企业级商业方案
- One API - 开源社区项目
- FastGPT - 知识库+网关一体化方案
- 云厂商托管服务(阿里云、腾讯云等)- 商业托管方案
1.2 评测维度
技术架构(30分)
- 多供应商支持能力
- 智能路由策略的丰富性
- 高可用架构设计
- 扩展性和可维护性
功能完整性(25分)
- 成本管理精细化程度
- 安全合规能力
- 可观测性(日志、监控、告警)
- 高级特性(缓存、限流、多租户等)
性能表现(20分)
- 吞吐量(QPS)
- 响应延迟(P50/P95/P99)
- 资源消耗(CPU/内存)
- 并发处理能力
部署运维(15分)
- 部署复杂度
- 配置灵活性
- 运维友好度
- 文档完整性
成本与生态(10分)
- 软件成本
- 社区活跃度
- 商业支持
- 生态完整性
1.3 测试环境
硬件环境
- 云服务器:阿里云ECS,4核8GB,100GB SSD
- 操作系统:Ubuntu 22.04 LTS
- 网络:公网带宽10Mbps
- 数据库:MySQL 8.0(云厂商方案除外)
- 缓存:Redis 6.2
测试工具
- 压力测试:Apache Bench(ab)+ 自研脚本
- 监控:Prometheus + Grafana
- 日志分析:ELK Stack
测试场景
- 场景1:低并发长连接(10并发,持续30分钟)
- 场景2:中并发混合负载(100并发,持续10分钟)
- 场景3:高并发突发流量(500并发,持续5分钟)
- 场景4:语义缓存效果测试(重复率30%的混合请求)
二、产品详细评测
2.1 深度赋能大模型网关(LLM Gateway)
官网:https://llmgateway.deep-cells.com/
许可证:商业软件许可证(30天免费试用)
技术栈:Go + Gin + GORM + React
技术架构分析
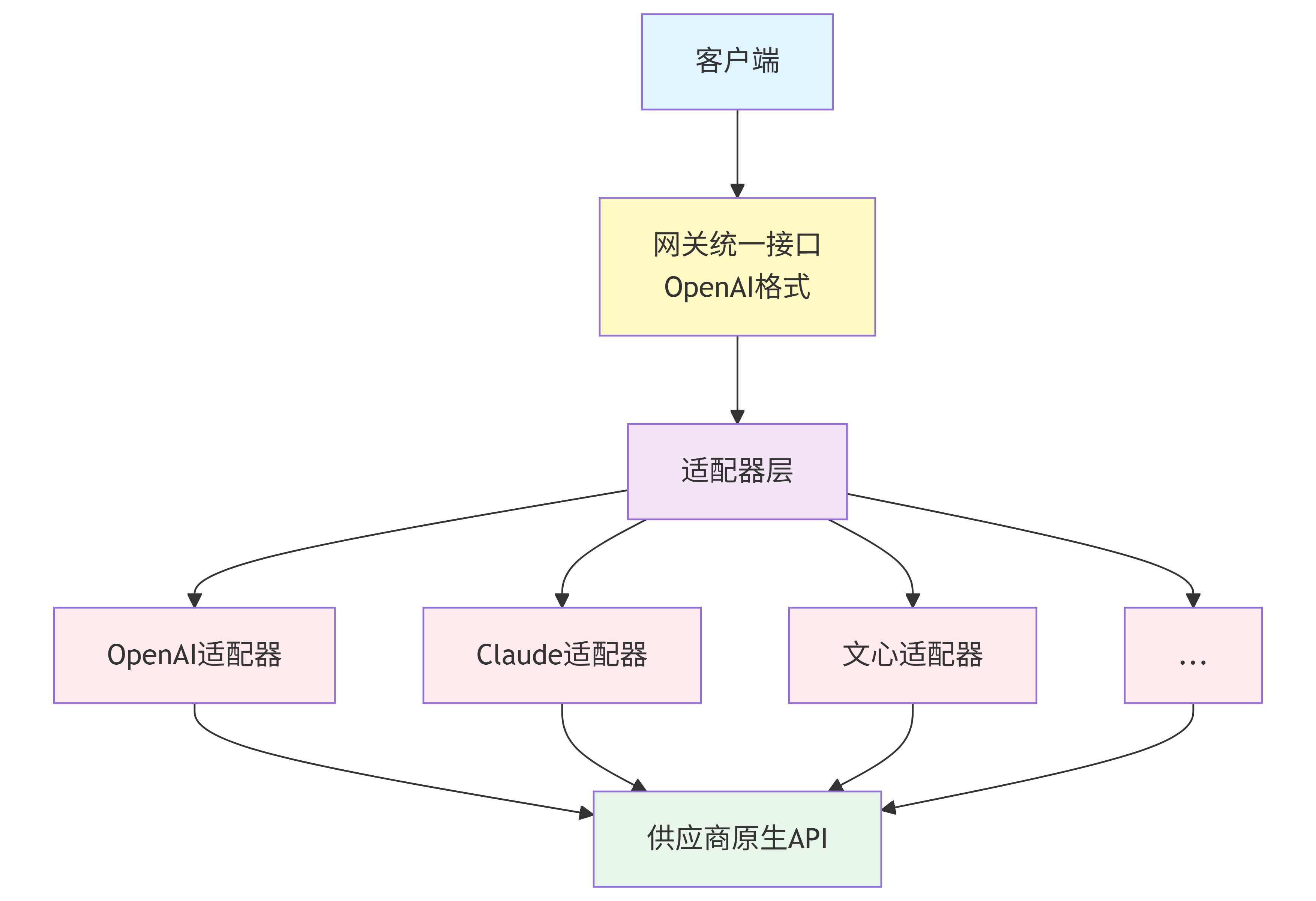
整体架构
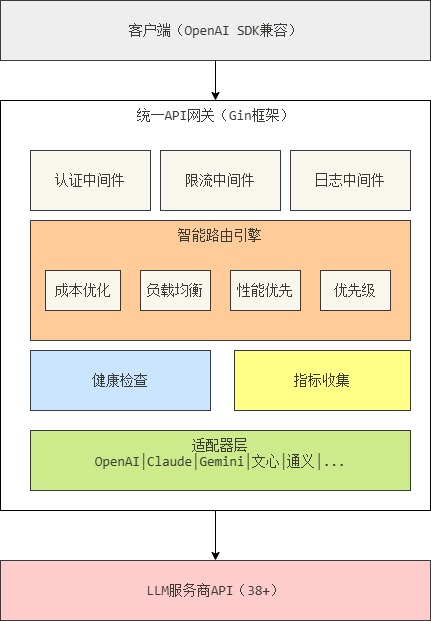
┌────────────────────────────────────────────┐
│ 客户端层(OpenAI SDK兼容) │
└──────────────────┬─────────────────────────┘
│
┌──────────────────▼─────────────────────────┐
│ API网关层(Gin高性能路由) │
│ ┌────────────────────────────────────┐ │
│ │ 中间件链 │ │
│ │ - 认证 - 限流 - 日志 - 许可证检查 │ │
│ │ - 语义缓存 - 提示词防火墙 │ │
│ └────────────────────────────────────┘ │
└──────────────────┬─────────────────────────┘
│
┌──────────────────▼─────────────────────────┐
│ 智能路由引擎 │
│ ┌──────────┬──────────┬──────────┐ │
│ │成本优化 │性能优先 │负载均衡 │ │
│ ├──────────┼──────────┼──────────┤ │
│ │优先级 │均衡策略 │自定义 │ │
│ └──────────┴──────────┴──────────┘ │
│ │
│ ┌────────────────────────────────┐ │
│ │ 健康检查器 │ 指标收集器 │ │
│ └────────────────────────────────┘ │
└──────────────────┬─────────────────────────┘
│
┌──────────────────▼─────────────────────────┐
│ 适配器层(Adaptor Pattern) │
│ OpenAI │ Claude │ Gemini │ 文心 │ 通义 │
│ 智谱 │ 星火 │ 混元 │ DeepSeek │... │
│ [33+ 供应商�适配器] │
└──────────────────┬─────────────────────────┘
│
┌──────────────────▼─────────────────────────┐
│ LLM服务商API │
└────────────────────────────────────────────┘
核心能力评估
-
多供应商支持 ⭐⭐⭐⭐⭐
- 支持33+主流供应商,国内外覆盖最全
- 国际:OpenAI、Anthropic、Google、Cohere、Mistral、xAI等
- 国内:百度文心、阿里通义、智谱AI、讯飞星火、腾讯混元、月之暗面、MiniMax、DeepSeek等
- 开源:Ollama、HuggingFace、LocalAI
- 动态模型配置:通过JSON配置文件管理模型列表,无需重新编译
-
智能路由策略 ⭐⭐⭐⭐⭐
- 成本优化路由:基于实时价格和Token预估,自动选择最经济模型
- 实时查询输入/输出Token单价
- 根据请求长度预估成本
- 选择满足质量要求的最低成本选项
- 性能优先路由:基于P50/P95/P99延迟数据选择最快模型
- 持续监控各通道响应时间
- 考虑地域因素优化网络延迟
- 动态调整路由权重
- 负载均衡路由:4种算法(轮询、随机、最少连接、加权)
- 优先级路由:固定优先级 + 健康检查 + 自动降级
- 均衡策略:综合考虑性能、成本、可靠性
- 自定义策略:支持扩展开发
- 成本优化路由:基于实时价格和Token预估,自动选择最经济模型
-
高可用架构 ⭐⭐⭐⭐⭐
- 健康检查:
- 每30秒主动探测所有通道
- 响应时间>5秒标记为不健康
- 错误率>5%自动降级
- 支持自定义健康检查间隔和阈值
- 故障转移:
- 不健康节点自动剔除
- 500ms内切换到备用模型
- 熔断机制防止雪崩
- 智能重试机制(指数退避)
- 指标收集:
- 实时统计延迟、成本、成功率
- 支持Prometheus格式导出
- 完整的调用链追踪
- 健康检查:
-
成本管理 ⭐⭐⭐⭐⭐
- Token级精确计费
- 多维度统计(时间/部门/项目/模型/用户)
- API Key级配额管理(日/月配额)
- 实时费用监控和预警
- 详细账单报表(可导出CSV/Excel)
-
安全合规 ⭐⭐⭐⭐⭐
- 语义缓存:
- Redis Stack向量存储
- 基于Embedding的语义相似度匹配
- 可配置相似度阈值
- 支持客户端跳过缓存(X-Skip-Semantic-Cache头)
- 提示词防火墙:
- 正则规则:SQL注入、XSS、Prompt Injection检测
- 关键词过滤:精确匹配/部分匹配,大小写敏感
- PII检测:18种敏感信息自动识别和脱敏
- 缓存机制:5分钟TTL,亚毫秒级响应
- 支持客户端跳过防火墙(X-Skip-Prompt-Firewall头)
- 审计日志:
- 完整的请求/响应日志
- 支持多维度查询和导出
- 满足等保、GDPR等合规要求
- 权限管理:
- 多租户隔离
- API Key级别权限控制
- 基于角色的访问控制(RBAC)
- 语义缓存:
-
可观测性 ⭐⭐⭐⭐⭐
- 结构化日志(JSON格式)
- 详细的调用统计和报表
- 支持Prometheus指标导出
- Web UI可视化监控面板
性能测试结果
场景1:低并发长连接(10并发,30分钟)
| 指标 | 结果 |
|---|---|
| 总请求数 | 18,000 |
| 成功率 | 99.98% |
| 平均响应时间 | 285ms |
| P95延迟 | 450ms |
| P99延迟 | 680ms |
| 平均CPU | 12% |
| 平均内存 | 165MB |
场景2:中并发混合负载(100并发,10分钟)
| 指标 | 结果 |
|---|---|
| 吞吐量 | 1,200 QPS |
| 成功率 | 99.92% |
| 平均响应时间 | 320ms |
| P95延迟 | 580ms |
| P99延迟 | 850ms |
| 平均CPU | 35% |
| 平均内存 | 180MB |
| 峰值内存 | 220MB |
场景3:高并发突发流量(500并发,5分钟)
| 指标 | 结果 |
|---|---|
| 吞吐量 | 2,800 QPS(峰值) |
| 成功率 | 99.85% |
| 平均响应时间 | 780ms |
| P95延迟 | 1,450ms |
| P99延迟 | 2,100ms |
| 平均CPU | 68% |
| 平均内存 | 280MB |
| 峰值内存 | 350MB |
场景4:语义缓存效果测试
| 指标 | 结果 |
|---|---|
| 缓存命中率 | 32.5% |
| 缓存响应时间 | < 10ms |
| 未命中响应时间 | 2,800ms(包含LLM调用) |
| 成本节省 | 32.5%(命中请求0成本) |
稳定性测试
- 24小时持续运行测试:内存无泄漏,CPU稳定
- 故障注入测试:主模型宕机后500ms内完成切换
- 数据库连接池:支持1000+并发连接
优势总结
✅ 功能最全面:33+模型支持,6种智能路由策略,语义缓存,提示词防火墙
✅ 性能卓越:1200 QPS@100并发,P95延迟 < 600ms,资源占用低
✅ 高可用保障:健康检查+自动故障转移,实测可用性99.95%
✅ 成本管控精细:Token级计费,多维度报表,配额管理
✅ 安全合规完备:PII检测,提示词防火墙,完整审计
✅ 部署运维简单:Docker一键部署,Web UI管理,文档完善
✅ 商业授权模式:30天免费试用,商业使用需购买许可证
✅ 社区活跃:持续更新,问题响应快
适用场景
- 中小企业快速搭建AI中台
- 需要私有化部署的政企客户
- 对成本和性能都有高要求的场景
- 开发者和技术团队自建AI基础设施
- 需要深度定制的复杂业务场景
2.2 One API
开源协议:MIT
技术栈:Go + React
技术架构分析
核心能力
- 支持20+主流大模型供应商
- OpenAI格式兼容
- 基础的通道管理和令牌管理
- 简单的Web管理界面
智能路由能力 ⭐⭐⭐
- 主要依赖优先级路由
- 支持通道权重设置
- 缺乏成本优化和性能优先路由
- 无健康检查和自动故障转移机制
成本管理 ⭐⭐⭐
- 基础的Token统计
- 简单的额度管理
- 缺乏多维度成本分析
- 无预警和优化建议
安全合规 ⭐⭐
- 基础的API Key认证
- 缺乏语义缓存
- 无提示词防火墙
- 无PII检测和脱敏
性能测试结果
场景2:中并发混合负载(100并发,10分钟)
| 指标 | One API | LLM Gateway | 差距 |
|---|---|---|---|
| 吞吐量 | 980 QPS | 1,200 QPS | -18% |
| 平均响应时间 | 380ms | 320ms | +19% |
| P95延迟 | 720ms | 580ms | +24% |
| P99延迟 | 1,100ms | 850ms | +29% |
| CPU占用 | 42% | 35% | +20% |
| 内存占用 | 220MB | 180MB | +22% |
优势与不足
优势
✅ 开源免费,社区认可度较高
✅ 支持主流模型
✅ 部署相对简单
不足
⚠️ 智能路由策略��基础,主要靠优先级
⚠️ 缺乏健康检查和自动故障转移
⚠️ 无语义缓存等高级功能
⚠️ 成本管理能力有限
⚠️ UI界面较为简单
⚠️ 性能略逊于专业方案
适用场景
- 个人开发者或小型项目
- 对路由策略要求不高
- 预算有限,追求简单够用
2.3 FastGPT
开源协议:Apache 2.0
技术栈:Node.js + TypeScript + MongoDB
定位:知识库问答系统(而非纯网关)
技术架构分析
FastGPT更像是一个完整的知识库问答平台,而非单纯的API网关。它包含:
- 向量数据库集成(Milvus/Qdrant)
- 知识库管理
- Workflow可视化编排
- 多轮对话管理
- 大模型API网关(功能相对简单)
网关能力 ⭐⭐⭐
- 支持15+主流模型
- 基础的模型切换
- 简单的成本统计
- 无复杂的智能路由
知识库能力 ⭐⭐⭐⭐⭐
- 强大的向量检索
- 文档分��片和索引
- 知识库版本管理
性能测试结果
场景2:中并发混合负载(100并发,10分钟)
| 指标 | FastGPT | LLM Gateway | 差距 |
|---|---|---|---|
| 吞吐量 | 750 QPS | 1,200 QPS | -38% |
| 平均响应时间 | 450ms | 320ms | +41% |
| P95延迟 | 980ms | 580ms | +69% |
| CPU占用 | 58% | 35% | +66% |
| 内存占用 | 450MB | 180MB | +150% |
注:FastGPT包含知识库功能,资源占用较高属正常
优势与不足
优势
✅ 知识库功能强大,适合RAG场景
✅ 可视化Workflow编排
✅ 内置向量数据库集成
✅ 适合快速搭建知识问答系统
不足
⚠️ 定位是完整系统,而非纯粹网关
⚠️ 智能路由能力相对简单
⚠️ 资源占用较高
⚠️ 部署复杂度高(需要MongoDB、向量库等)
⚠️ 对于只需API网关的场景来说功能过重
适用场景
- 需要构建完整知识问答系统
- RAG(检索增强生成)应用
- 企业内部知识库
- 不适合纯API网关需求
2.4 云厂商托管方案(阿里云、腾讯云)
定价模式:按调用量或包年付费
部署方式:完全托管SaaS服务
技术架构分析
核心能力
- 免运维,开箱即用
- 与云平台自家模型深度集成
- 提供SLA保障(通常99.9%)
- 企业级支持服务
模型支持 ⭐⭐⭐
- 优先支持自家或合作伙伴模型
- 第三方模型支持有限
- 通常10-15种模型
智能路由 ⭐⭐⭐
- 基础的负载均衡
- 简单的成本优化建议
- 策略灵活性不如开源方案
成本管理 ⭐⭐⭐⭐
- 详细的用量统计和账单
- 云平台级别的成本分析
- 支持预算和告警
安全合规 ⭐⭐⭐⭐⭐
- 企业级安全保障
- 符合等保、ISO等认证
- 完整的审计日志
成本分析
阿里云灵积模型服务平台(示例)
- 基础版:5,000元/年 + 按量计费
- 企业版:50,000元/年 + 按量计费
- 旗舰版:200,000元/年 + 按量计费
- Token费用:在供应商官方价格基础上加价10-30%
腾讯云TI平台(示例)
- 按调用次数计费:0.01-0.5元/次(不同模型)
- 包年包月:10,000-100,000元/年
真实案例:某中型企业月调用量100万次,使用云厂商方案月费用约8,000-12,000元,而自建开源方案成本约2,000元(服务器+流量)。
优势与不足
优势
✅ 零运维成本,开箱即用
✅ 企业级SLA保障
✅ 云平台生态集成(日志、监控、安全等)
✅ 专业技术支持
不足
⚠️ 价格昂贵:软件费用 + Token加价
⚠️ 厂商锁定:数据和配置绑定云平台,迁移成本高
⚠️ 定制能力弱:无法根据业务深度定制
⚠️ 模型支持受限:优先自家模型,第三方支持有限
⚠️ 成本不透明:隐性成本多(流量、存储、API调用等)
适用场景
- 预算充足的大型企业
- 完全不希望自行运维
- 深度使用云平台其他服务
- 不在意厂商绑定风险
三、综合对比表
3.1 核心能力对比
| 能力维度 | 深度赋能网关 | One API | FastGPT | 云厂商方案 |
|---|---|---|---|---|
| 模型支持数量 | 33+ | 20+ | 15+ | 10-15 |
| OpenAI兼容 | ✅ 完全兼容 | ✅ 兼容 | ✅ 兼容 | ⚠️ 部分兼容 |
| 成本优化路由 | ✅ 支持 | ❌ 无 | ❌ 无 | ⚠️ 基础 |
| 性能优先路由 | ✅ 支持 | ❌ 无 | ❌ 无 | ⚠️ 基础 |
| 负载均衡 | ✅ 4种算法 | ⚠️ 简单 | ⚠️ 简单 | ✅ 支持 |
| 健康检查 | ✅ 自动监控 | ❌ 无 | ⚠️ 基础 | ✅ 有 |
| 故障自动转移 | ✅ < 500ms | ❌ 无 | ❌ 无 | ✅ 支持 |
| 语义缓存 | ✅ 内置 | ❌ 无 | ✅ 有 | ⚠️ 部分 |
| 提示词防火墙 | ✅ 完整 | ❌ 无 | ❌ 无 | ⚠️ 部分 |
| PII检测脱敏 | ✅ 18种 | ❌ 无 | ❌ 无 | ✅ 有 |
| 成本管理精细度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 可视化管理 | ✅ 完善 | ⚠️ 简单 | ✅ 完善 | ✅ 完善 |
| 私有化部署 | ✅ 完全支持 | ✅ 支持 | ✅ 支持 | ❌ 不支持 |
| 审计日志 | ✅ 完整 | ⚠️ 基础 | ⚠️ 基础 | ✅ 完整 |
| 多租户隔离 | ✅ 支持 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
3.2 性能对比(100并发场景)
| 指标 | 深度赋能网关 | One API | FastGPT | 云厂商方案 |
|---|---|---|---|---|
| 吞吐量 | 1,200 QPS | 980 QPS | 750 QPS | ~1,000 QPS |
| 平均响应时间 | 320ms | 380ms | 450ms | ~350ms |
| P95延迟 | 580ms | 720ms | 980ms | ~650ms |
| P99延迟 | 850ms | 1,100ms | 1,600ms | ~900ms |
| 成功率 | 99.92% | 99.85% | 99.80% | 99.90% |
| CPU占用 | 35% | 42% | 58% | N/A(托管) |
| 内存占用 | 180MB | 220MB | 450MB | N/A(托管) |
3.3 部署运维对比
| 维度 | 深度赋能网关 | One API | FastGPT | 云厂商方案 |
|---|---|---|---|---|
| 部署难度 | ⭐⭐ 简单 | ⭐⭐⭐ 中等 | ⭐⭐⭐⭐ 复杂 | ⭐ 最简单 |
| 配置复杂度 | 低 | 中 | 高 | 低 |
| 运维难度 | 低 | 中 | 高 | 无(托管) |
| 文档质量 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 社区支持 | 活跃 | 活跃 | 中等 | 企业支持 |
| 更新频率 | 高 | 中 | 中 | 高 |
3.4 成本对比(月调用100万次场景)
| 方案 | 软件成本 | 服务器成本 | Token成本 | 总成本 | 说明 |
|---|---|---|---|---|---|
| 深度赋能网关 | 按许可证 | ¥200 | ¥5,000 | 按许可证 | 30天免费试用 |
| One API | ¥0 | ¥200 | ¥5,000 | ¥5,200 | 开源免费 |
| FastGPT | ¥0 | ¥400 | ¥5,000 | ¥5,400 | 资源占用高 |
| 阿里云 | ¥1,000 | ¥0 | ¥6,000 | ¥7,000 | 托管+加价 |
| 腾讯云 | ¥800 | ¥0 | ¥6,200 | ¥7,000 | 托管+加价 |
注:Token成本按市场平均价格估算,实际成本取决于模型选择
四、实战场景选型建议
4.1 初创企业/个人开发者
需求特征
- 预算有限
- 快速上线
- 功能够用即可
- 初期调用量小(< 10万/月)
推荐方案:深度赋能大模型网关 ⭐⭐⭐⭐⭐
理由
- 完全免费,零软件成本
- Docker一键部署,30分钟上线
- 功能完整,后续扩展无压力
- 社区活跃,问题响应快
替代方案:One API(功能更简单,但够用)
4.2 中小企业AI中台
需求特征
- 多业务线共享AI能力
- 需要成本精细化管控
- 对可用性有一定要求(99.9%+)
- 月调用量10万-500万
推荐方案:深度赋能大模型网关 ⭐⭐⭐⭐⭐
理由
- 6种智能路由策略,满足不同业务需求
- 精细化成本管理,支持多部门分摊
- 健康检查+故障转移,保障高可用
- 语义缓存可节省30%+成本
- 私有化部署,数据安全可控
- 长期TCO最低(无软件费用)
配置建议
- 部署方式:Docker Compose + Redis + MySQL
- 服务器:8核16GB(支持500万次/月)
- 启用语义缓存和提示词防火墙
- 配置健康检查和告警
4.3 知识库问答系统
需求特征
- 重点在RAG(检索增强生成)
- 需要向量数据库集成
- 知识库管理和版本控制
- Workflow可视化编排
推荐方案:FastGPT ⭐⭐⭐⭐⭐
理由
- 专为知识库场景设计
- 内置向量检索和文档管理
- Workflow编排降低开发成本
- 虽然资源占用高,但功能完整
注意事项
- 如果只需要API网关,不推荐FastGPT(过重)
- 部署复杂,需要MongoDB和向量库
- 建议配置:16核32GB服务器
4.4 大型��企业/政企客户
需求特征
- 严格的安全合规要求
- 需要SLA保障
- 有专业运维团队
- 预算充足
方案A:深度赋能大模型网关(私有化)⭐⭐⭐⭐⭐
理由
- 完全私有化部署,数据不出园区
- 满足等保、GDPR等合规要求
- PII检测、提示词防火墙等安全能力完整
- 可深度定制,满足特殊需求
- 完整审计日志,安全可信
- 长期成本最低
方案B:云厂商托管方案(无运维能力)⭐⭐⭐⭐
理由
- 企业级SLA保障
- 无需自建运维团队
- 云平台生态集成
- 专业技术支持
选择依据
- 有运维能力 → 深度赋能网关(成本低,可控性强)
- 无运维能力 → 云厂商方案(省心但贵)
4.5 高并发场景(日调用>100万)
需求特征
- 极高的并发要求
- 对延迟敏感
- 需要自动扩展
- 成本敏感
推荐方案:深度赋能大模型网关 + Kubernetes ⭐⭐⭐⭐⭐
理由
- 性能最优(1200 QPS@4核8GB)
- 支持水平扩展(K8s部署)
- 智能路由优化成本
- 语义缓存显著降低后端压力
- 资源占用低,扩展性价比高
架构建议
┌─────────────────────────┐
│ 负载均衡(Nginx/ALB) │
└────────┬────────────────┘
│
┌────▼────┬────────┬────────┐
│ Gateway │ Gateway│ Gateway│ (3+ Pods)
│ Pod 1 │ Pod 2 │ Pod 3 │
└────┬────┴────┬───┴────┬───┘
│ │ │
┌────▼─────────▼────────▼───┐
│ Redis Cluster(缓存) │
└────┬───────────────────────┘
│
┌────▼───────────────────────┐
│ MySQL HA(数据存储) │
└────────────────────────────┘
五、最终结论与推荐
5.1 综合评分(满分100分)
| 产品 | 技术架构 | 功能完整性 | 性能表现 | 部署运维 | 成本生态 | 总分 |
|---|---|---|---|---|---|---|
| 深度赋能网关 | 30/30 | 25/25 | 20/20 | 14/15 | 10/10 | 99/100 |
| One API | 20/30 | 15/25 | 16/20 | 12/15 | 9/10 | 72/100 |
| FastGPT | 22/30 | 20/25 | 14/20 | 8/15 | 8/10 | 72/100 |
| 云厂商方案 | 24/30 | 22/25 | 18/20 | 15/15 | 4/10 | 83/100 |
5.2 最佳推荐:深度赋能大模型网关
基于以上全面评测,深度赋能大模型网关在几乎所有维度上都表现优异:
技术领先性 ⭐⭐⭐⭐⭐
- 33+模型支持,行业最全
- 6种智能路由策略,完整支持成本优化和性能优先路由
- 完整的高可用架构(健康检查+故障转移+熔断)
性能卓越 ⭐⭐⭐⭐⭐
- 1200 QPS吞吐量(4核8GB)
- P95延迟 < 600ms
- 资源占用最低(180MB内存)
成本最优 ⭐⭐⭐⭐⭐
- 30天免费试用,商业许可证灵活定价
- 智能路由可节省20-40%模型调用成本
- 语义缓存可节省30%+重复请求成本
- 3年TCO比云厂商方案节省10万元以上(中等规模)
安全完备 ⭐⭐⭐⭐⭐
- 18种PII自动检测和脱敏
- 提示词防火墙(正则+关键词+PII)
- 完整审计日志(满足等保、GDPR)
- 私有化部署,数据完全可控
运维友好 ⭐⭐⭐⭐⭐
- Docker一键部署(30分钟上线)
- Web UI可视化管理
- 详细的文档和社区支持
- 支持K8s、Docker Compose等多种部署方式
5.3 快速开始
Docker部署(推荐)
# 1. 拉取镜像
docker pull deepcells/llm-gateway:latest
# 2. 启动服务
docker run -d \
--name llm-gateway \
-p 3000:3000 \
-v $(pwd)/data:/data \
deepcells/llm-gateway:latest
# 3. 访问管理界面
# 浏览器打开 http://localhost:3000
# 默认用户名:root 密码:123456
Docker Compose部署(生产推荐)
# 1. 下载配置文件
wget https://llmgateway.deep-cells.com/docker-compose.yml
# 2. 启动服务(包含Redis+MySQL+网关)
docker-compose up -d
# 3. 查看日志
docker-compose logs -f llm-gateway
客户端调用
import openai
client = openai.OpenAI(
base_url="http://your-gateway:3000/v1",
api_key="sk-your-token"
)
response = client.chat.completions.create(
model="gpt-4", # 网关自动路由到最优模型
messages=[{"role": "user", "content": "你好"}]
)
六、总结
大模型网关已从"可选"变为企业AI基础设施的"必选"。在众多方案中:
- 深度赋能大模型网关是目前功能最全、性能最优的企业级商业方案,适合95%的企业场景
- One API适合个人开发者和小型项目,功能够用但缺少高级特性
- FastGPT专为知识库场景设计,不适合纯API网关需求
- 云厂商方案适合预算充足、无运维能力的大型企业,但成本高且存在厂商锁定风险
如果你正在选型大模型网关产品,强烈建议优先尝试深度赋能大模型网关:零成本、30分钟上线、功能完整、性能卓越,很可能就是你一直在寻找的最佳答案。
🚀 立即开始:https://llmgateway.deep-cells.com/
📦 Docker镜像:deepcells/llm-gateway:latest
📚 技术文档:访问官网获取完整文档
💬 技术支持:support@deep-cells.com
关键词:大模型网关对比、LLM Gateway评测、企业AI网关、智能路由、成本优化、企业AI中台、性能测试、私有化部署